ReactiveProgramming
ReactiveProgramming에 대해서 적어봤습니다.

주제 선정 이유
백엔드 개발을 진행하면서 Spring Boot를 기반으로 API를 구현하다 보니, 대부분의 요청 처리를 동기 방식으로
구성하는 것이 자연스럽게 느껴졌지만, 동시에 대량의 요청이나 외부 API 호출과 같은 상황에서는 이러한 구조가
비효율적으로 동작할 수 있다는 점을 체감하게 되었습니다.
그러던 중 Reactive Programming과 Spring WebFlux를 접하게 되었고,기존의 요청-응답 기반 동기 처리 방식과는
다르게 데이터 흐름과 이벤트를 중심으로 비동기 처리를 수행하는 방식이라는 점이 흥미롭게 느껴졌으며, 적은 리소스로
더 많은 요청을 처리할 수 있다는 점에서 백엔드 구조 설계에 있어 중요한 개념이라는 생각이 들었습니다.
그래서 이번 글에서 Reactive Programming 핵심 개념인 논블로킹 I/O 기반의 처리 방식, Publisher-Subscriber 모델, 데이터 스트림의 흐름 제어, 그리고 Spring WebFlux에서의 동작 구조까지를 중심으로 내부 동작 원리를 정리해보고자 합니다.
ReactiveProgramming이 뭘까?
Reactive Programming은 데이터의 변화를 중심으로 동작하는 프로그래밍 패러다임으로, 값이 변경되었을 때 이를
감지하고 자동으로 반응하여 필요한 로직을 수행하는 방식인데 기존의 동기 방식 프로그래밍에서는 요청이 발생하면
하나의 흐름 안에서 순차적으로 작업이 처리되며, 특정 작업이 완료될 때까지 다음 작업이 대기하는 구조를 가지지만, Reactive Programming에서는 이러한 흐름을 이벤트와 데이터 스트림 단위로 나누어 처리하게 됩니다.
특히 데이터는 단순한 값이 아니라 시간에 따라 변화하는 흐름(Stream) 으로 다루어지며, 이 흐름을 구독(Subscribe)하고 있던 컴포넌트는 데이터가 변경될 때마다 자동으로 이를 전달받아 처리하게 되는데 이러한 구조는 Publisher가
데이터를 발행하고, Subscriber가 이를 구독하는 형태로 구성되며, 중간에서 데이터를 가공하거나 변환하는
Operator를 통해 하나의 흐름을 구성하게 됩니다.
결과적으로 Reactive Programming은 데이터의 흐름을 중심으로 비동기 처리를 수행하고, 이벤트에 반응하는 구조를 통해 더 효율적이고 유연한 시스템을 구성할 수 있도록 해주는 프로그래밍 방식이라고 정리할 수 있습니다.
Publisher, Subscriber, Operator
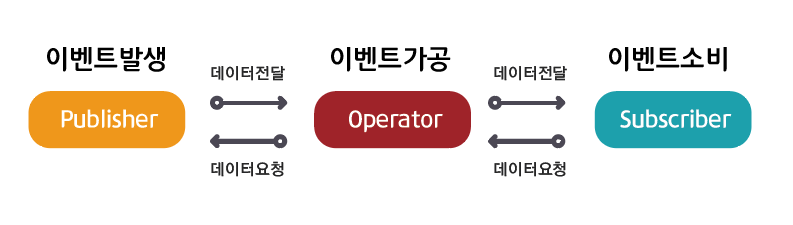
데이터 흐름을 중심으로 동작하며, 이 흐름은 크게 Publisher, Subscriber, Operator 세 가지 요소로 구성이 되고
각 요소는 역할이 명확하게 나뉘어 있으며, 이들이 연결되면서 하나의 데이터 스트림을 형성하게 됩니다.
Publisher
데이터를 생성하고 발행하는 주체로, 데이터 스트림의 시작점이라고 볼 수 있는데 데이터는 한 번에 하나씩 또는 여러 개의 이벤트 형태로 발행되며, 이를 구독하고 있는 Subscriber에게 전달됩니다.
예를 들어 데이터베이스 조회 결과나 외부 API 응답과 같은 값이 Publisher를 통해 스트림 형태로 전달될 수 있습니다.
Subscriber
Subscriber는 Publisher가 발행하는 데이터를 구독하고 처리하는 역할을 하고 데이터가 발행될 때마다 이를
전달받아 로직을 수행하게 되며, 필요에 따라 데이터 처리 방식이나 흐름을 제어할 수 있습니다.
또한 Subscriber는 단순히 데이터를 받는 것뿐만 아니라, 얼마나 많은 데이터를 받을지 요청하는 방식으로 흐름을 조절할 수도 있는데, 이를 통해 과도한 데이터 처리로 인한 부담을 줄일 수 있습니다.
Operator
Operator는 Publisher와 Subscriber 사이에서 데이터를 가공하거나 변환하는 역할을 하고 데이터를 필터링하거나(filter), 변환하거나(map), 특정 조건에 따라 흐름을 변경하는 등의 작업을 수행하며, 여러 개의 Operator를
연결하여 하나의 처리 파이프라인을 구성할 수 있습니다.
이처럼 Publisher → Operator → Subscriber로 이어지는 구조를 통해 데이터는 단순한 값이 아닌 흐름으로
처리되며, 각 단계에서의 역할 분리를 통해 비동기 데이터 처리를 보다 유연하고 효율적으로 구성할 수 있습니다.
Non-Blocking과 Backpressure
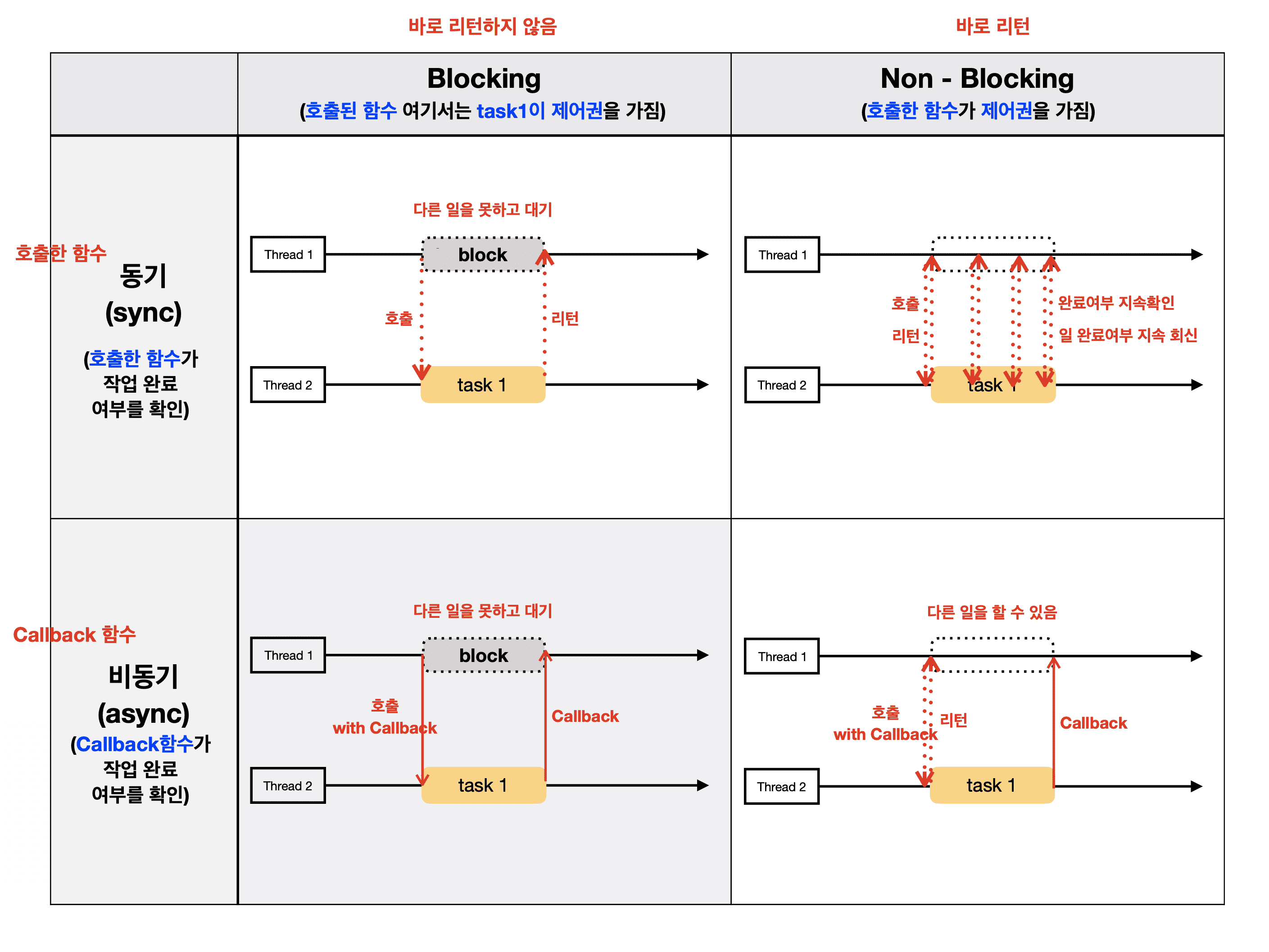
Reactive Programming의 가장 큰 특징 중 하나는 Non-Blocking 기반으로 동작한다는 점인데 기존의 동기 방식에서는
하나의 요청이 들어오면 해당 작업이 완료될 때까지 스레드가 점유되며 대기하게 되지만, 논블로킹 방식에서는 작업이
완료되지 않았더라도 스레드를 반환하고 다른 작업을 처리할 수 있습니다.
예를 들어 외부 API 호출이나 데이터베이스 조회와 같은 I/O 작업이 발생했을 때, 동기 방식에서는 응답이 올 때까지 기다리지만, 논블로킹 방식에서는 결과를 기다리는 동안 다른 요청을 처리할 수 있기 때문에 적은 리소스로 더 많은
요청을 처리할 수 있게 됩니다.
또한 Reactive Programming에서는 데이터의 흐름을 제어하기 위한 개념으로 Backpressure를 제공하는데 Subscriber가 처리할 수 있는 속도에 맞춰 Publisher가 데이터를 발행하도록 조절하는 방식으로, 데이터가 과도하게 쏟아지는 상황을 방지하고 시스템의 안정성을 유지하는 역할을 하며 단순히 데이터를 빠르게 처리하는 것이 아니라
처리 가능한 만큼만 데이터를 흐르게 하여 시스템 전체의 균형을 유지하는 것이 핵심입니다.
Backpressure 전략
Backpressure는 데이터 처리 속도를 조절하여 시스템의 안정성을 유지하기 위한 중요한 개념으로, 상황에 따라 다양한 전략을 선택하여 적용할 수 있습니다.
| 전략 | 설명 |
|---|---|
IGNORE 전략 | Backpressure를 적용하지 않는다. |
ERROR 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찼을 경우, Exception을 발생시키는 전략 |
DROP 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찼을 경우, 버퍼 밖에서 대기하는 먼저 emit된 데이터부터 Drop 시키는 전략 |
LATEST 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찼을 경우, 버퍼 밖에서 대기하는 가장 최근 emit된 데이터부터 버퍼에 채우는 전략 |
BUFFER 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찼을 경우, 버퍼 안에 있는 데이터부터 Drop 시키는 전략 |
Spring WebFlux

실제 백엔드에서 구현한 대표적인 기술이 바로 Spring WebFlux인데 기존 Spring MVC는 요청마다 하나의 스레드를
할당하는 동기 방식으로 동작하지만, WebFlux는 Non-Blocking 기반으로 동작하며 적은 수의 스레드로도 많은 요청을 처리할 수 있도록 설계되었는데 이러한 구조는 특히 외부 API 호출이나 데이터베이스와 같은 I/O 작업이 많은 환경에서 큰 장점을 가지며, 스레드를 효율적으로 사용함으로써 높은 동시성을 처리할 수 있습니다.
또한 WebFlux는 Reactive Streams 표준을 기반으로 하며, 내부적으로 Publisher와 Subscriber 구조를 그대로
활용하여 데이터를 흐름 단위로 처리하게 되는데 앞에서 살펴본 Reactive Programming 개념이 실제로 적용된
프레임워크라고 볼 수 있습니다.
Mono와 Flux
Spring WebFlux에서는 데이터를 처리하기 위해 Mono와 Flux라는 두 가지 타입을 사용합니다.
Mono
0개 또는 1개의 데이터를 처리하는 Publisher로, 단일 결과를 반환하는 경우에 사용되는데 예를 들어 사용자 한 명을
조회하거나, 하나의 응답 값을 반환하는 경우에 적합합니다.
1
Mono<String> mono = Mono.just("Hello");
Flux
0개 이상의 여러 데이터를 처리하는 Publisher로, 여러 개의 데이터를 스트림 형태로 전달할 때 사용되는데 예를 들어 여러 개의 데이터를 조회하거나, 이벤트 스트림을 처리하는 경우에 사용됩니다.
1
Flux<Integer> flux = Flux.just(1, 2, 3, 4);
이처럼 Mono와 Flux를 통해 단일 데이터와 다중 데이터 흐름을 명확하게 구분할 수 있으며, 데이터를 단순 값이 아닌 흐름으로 다루는 것이 Reactive Programming의 핵심입니다.
그래서 어떻게 쓰라고?

Reactive Programming은 내부 개념이나 동작 원리를 모두 외우는 것보다, 어떤 상황에서 왜 사용하는지 이해하고
적절한 곳에 적용할 수 있는 수준으로 익히는 것이 중요하다고 생각합니다.
백엔드 개발에서는 특히 외부 API 호출이나 데이터베이스와 같이 I/O 작업이 많은 경우, 동기 방식으로 처리하면
스레드가 대기 상태에 머무르게 되어 리소스 낭비가 발생할 수 있지만, Reactive 방식에서는 논블로킹으로 처리하여
하나의 스레드로 더 많은 요청을 처리할 수 있습니다.
예를 들어 여러 개의 외부 API를 동시에 호출하거나, 대량의 데이터를 비동기로 처리해야 하는 경우에는 WebFlux와 Mono, Flux를 활용하여 효율적으로 처리할 수 있습니다.
1
2
3
4
5
Mono<String> result =
webClient.get()
.uri("https://api.example.com")
.retrieve()
.bodyToMono(String.class);
위와 같이 사용하면 외부 API 호출을 논블로킹 방식으로 처리할 수 있으며, 응답을 기다리는 동안 다른 작업을 수행할 수 있기 때문에 전체적인 처리 효율을 높일 수 있고 여러 개의 데이터를 동시에 처리해야 하는 경우에는 Flux를 활용하여 데이터 흐름을 하나의 스트림으로 구성하고, 다양한 Operator를 통해 가공할 수 있습니다.
결과적으로 Reactive Programming은 단순히 새로운 문법을 사용하는 것이 아니라,동시성과 I/O 처리 성능이 중요한
상황에서 시스템을 더 효율적으로 설계하기 위한 선택지라고 이해하는 것이 중요합니다.
마무리
Reactive Programming을 정리하면서 느낀 핵심을 다시 정리해보면 다음과 같습니다.
Reactive Programming은 데이터의 흐름을 중심으로 비동기 처리를 수행하는 프로그래밍 패러다임입니다.Publisher,Subscriber,Operator구조를 통해 데이터 스트림을 구성하고, 이벤트 기반으로 데이터를 처리할 수 있습니다.Non-Blocking과Backpressure를 통해 리소스를 효율적으로 사용하면서도 안정적인 데이터 흐름을 유지할 수
있습니다.Spring WebFlux와Mono,Flux를 활용하면 높은 동시성과 I/O 처리 효율이 중요한 환경에서 더욱 효과적인
시스템을 구성할 수 있습니다.Reactive Programming은 단순한 기술이 아니라, 데이터 흐름과 동시성을 고려한 시스템 설계를 위한 중요한 접근 방식입니다.