JPA Fetch Join vs 분리 조회
JPA Fetch Join vs 분리 조회에 대해서 적어봤습니다.

주제 선정 이유
프로젝트에서 JPA를 사용해 데이터를 조회하다 보면 게시글과 작성자, 주문과 주문 상품처럼 하나의 데이터를
사용하기 위해 여러 연관 데이터를 함께 조회해야 하는 상황이 자주 발생하는데 이 과정에서 자연스럽게 fetch join을 활용하게 되고, 한 번의 쿼리로 연관 엔티티를 조회할 수 있어 N+1 문제를 해결하는 방법으로 익숙하게 사용하게 됩니다.
하지만 프로젝트를 진행하면서 모든 상황에서 fetch join을 사용하는 것이 적절한지, 혹은 서비스 계층에서 다른 Service를 호출하여 데이터를 조합하는 방식은 어떤 차이가 있는지에 대한 고민이 생기게 되는데 두 방식 모두 실제로 많이 사용되지만, 각각이 어떤 기준에서 선택되어야 하는지에 대해서는 명확히 정리하지 못한 채 사용하는 경우가
많습니다.
그래서 이번 글에서는 Fetch join 방식과 서비스 계층에서 데이터를 조합하는 방식의 차이와 특징을 비교하고, 상황에
따라 어떤 방식을 선택하는 것이 적절한지를 중심으로 정리해보고자 합니다.
Fetch Join과 서비스 분리 조회가 뭘까?
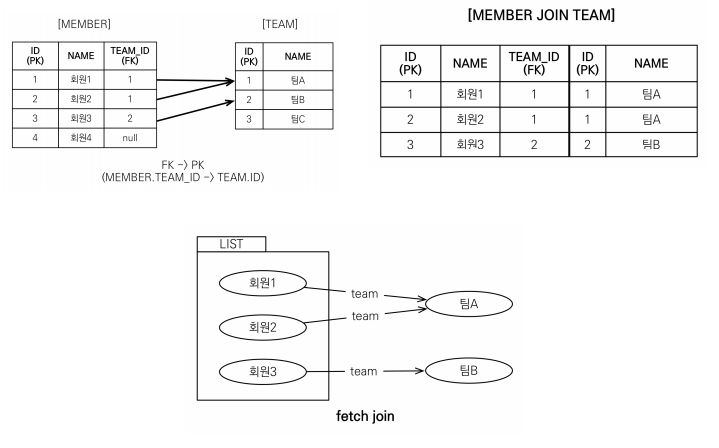
Fetch Join
JPA에서 Fetch Join은 연관된 엔티티를 하나의 쿼리로 함께 조회하기 위해 사용하는 JPQL 문법으로, 연관 데이터 조회 전략을 제어하는 중요한 방법 중 하나이다.
기본적으로 JPA의 연관 관계는 LAZY로 설정되는 경우가 많기 때문에, 처음 엔티티를 조회할 때는 연관된 데이터를
가져오지 않고 실제로 해당 데이터를 사용하는 시점에 추가 쿼리가 실행된다. 이러한 방식은 불필요한 데이터를 미리
조회하지 않아 효율적일 수 있지만, 여러 개의 연관 데이터를 함께 사용하는 상황에서는 반복적인 추가 조회가 발생할
수 있다는 단점이 존재한다.
예를 들어 게시글 목록을 조회한 뒤 각 게시글의 작성자 정보를 조회하는 경우, 게시글 목록을 가져오는 쿼리가 1번
실행된 이후 각 게시글마다 작성자 정보를 조회하는 쿼리가 추가로 실행되면서 총 N+1번의 쿼리가 발생하게 되며
이처럼 하나의 조회 이후 연관 데이터 조회를 위해 추가 쿼리가 반복되는 구조를 N+1 문제라고 하며, 조회 대상이
많아질수록 성능 저하로 이어질 수 있다.
이러한 문제를 해결하기 위해 Fetch Join을 사용할 수 있으며, 이를 통해 연관된 엔티티를 하나의 쿼리로 함께
조회함으로써 추가적인 쿼리 실행을 방지할 수 있어서 조회 시점에 필요한 데이터를 미리 함께 가져와서 쿼리수를
줄이고 실행시간을 줄이는 방식이다.
1
2
@Query("select p from Post p join fetch p.user")
List<Post> findAllWithUser();
서비스 분리 조회
Fetch Join과는 다른 접근 방식으로, Repository에서 모든 연관 데이터를 한 번에 조회하는 대신 서비스 계층에서
필요한 데이터를 각각 조회해 조합하는 방식도 사용할 수 있습니다.
예를 들어 게시글을 조회한 뒤 작성자 정보가 필요하다면 PostService에서 게시글을 조회한 뒤 UserService를 호출해 사용자 정보를 가져오는 방식으로 데이터를 조합할 수 있습니다.
1
2
Post post = postRepository.findById(id);
User user = userService.findById(post.getUserId());
이 코드는 PostService 내부에서 게시글을 조회하기 위해 PostRepository를 호출하고, 이후 작성자 정보가 필요할
경우 UserService를 통해 사용자 정보를 조회하는 흐름이며 이 방식의 특징은 도메인 책임이 명확하게 분리된다는
점이며 게시글 데이터 접근은 PostRepository, 사용자 정보 조회는 UserService가 담당하게 되어 각 도메인의 역할을 유지하면서 데이터를 사용할 수 있습니다.
다만 조회 쿼리가 여러 번 실행될 수 있기 때문에 상황에 따라 성능 측면에서는 불리해질 수 있으며, 이러한 이유로 실제 프로젝트에서는 조회 성능이 중요한 경우 Fetch Join을 사용하고 도메인 책임 분리가 중요한 경우 서비스 계층 조합
방식을 사용하는 경우가 많습니다.
그래서 어떻게 쓰라고?

정답은 무조건 하나를 고르는 것이 아니라, 조회 성능이 더 중요한지 아니면 도메인 책임 분리가 더 중요한지에 따라
선택해야 한다는 것이며 이 차이를 조금 더 직접적으로 확인해보기 위해, UserPet과 Pet 연관 관계를 기준으로
Fetch Join 방식과 서비스에서 분리 조회하는 방식을 테스트 코드로 비교해보았습니다.
테스트
이번 테스트는 다음과 같은 조건으로 진행했습니다.
- 반려동물 100건 생성
- UserPet 100건 생성
- 워밍업 2회
- 측정 5회 평균
- 평균 실행 시간과
SQL실행 수 비교
즉, 연관 데이터를 처음부터 한 번에 조회하는 방식과 ID만 먼저 조회한 뒤 필요한 데이터를 다시 조회하는 방식이 실제로 어느 정도 차이를 보이는지 확인하는 것이 목적이었습니다.
Fetch Join 방식
먼저 Fetch Join 방식은 UserPet을 조회하는 시점에 Pet까지 함께 가져오도록 구성했습니다.
1
2
3
4
5
6
7
8
@Query("SELECT up FROM UserPet up " +
"JOIN FETCH up.pet p " +
"WHERE up.user.usersId = :userId " +
"AND up.registrationStatus = :status")
List<UserPet> findAllByUserIdAndRegistrationStatusWithFetchJoin(
@Param("userId") UUID userId,
@Param("status") RegistrationStatus status
);
이후 테스트에서는 다음과 같이 UserPet을 조회한 뒤, 연관된 Pet의 이름을 접근하도록 구성했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
private void runFetchJoinRound() {
List<UserPet> userPets = userPetRepository.findAllByUserIdAndRegistrationStatusWithFetchJoin(
ownerId,
RegistrationStatus.APPROVED
);
long touched = userPets.stream()
.map(up -> up.getPet().getPetName())
.count();
assertThat(touched).isEqualTo(PET_COUNT);
}
이 방식은 처음 조회할 때 Pet까지 함께 가져오기 때문에, 이후 getPet().getPetName()을 호출하더라도 추가
SQL이 발생하지 않습니다.
서비스 분리 조회
반면 서비스 분리 조회 방식은 먼저 필요한 petId 목록만 조회한 뒤, 각 petId로 다시 Pet을 조회하는 흐름으로
구성했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
private void runSeparatedLookupRound() {
List<Long> petIds = userPetRepository.findPetIdsByUserIdAndRegistrationStatus(
ownerId,
RegistrationStatus.APPROVED
);
long touched = 0L;
for (Long petId : petIds) {
entityManager.clear();
petRepository.findById(petId).orElseThrow().getPetName();
touched++;
}
assertThat(touched).isEqualTo(PET_COUNT);
}
이 방식은 구조적으로는 단순하고 도메인 책임도 더 잘 분리할 수 있지만, 조회 대상이 많아질수록 반복 조회가 발생하기 때문에 성능 면에서는 불리해질 수 있습니다.
테스트 코드
실제 비교는 다음과 같이 워밍업 이후 여러 번 반복 실행해 평균 시간과 평균 SQL 실행 수를 측정하는 방식으로
진행했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Test
@DisplayName("fetch join vs 서비스 분리 조회 성능 비교 (no pagination, 100건)")
void compareFetchJoinWithSeparatedLookup() {
for (int i = 0; i < WARM_UP_ROUNDS; i++) {
runFetchJoinRound();
runSeparatedLookupRound();
}
Measurement fetchJoin = measure(this::runFetchJoinRound);
Measurement separatedLookup = measure(this::runSeparatedLookupRound);
System.out.printf("fetch join - 평균 시간: %.2f ms, 평균 SQL 실행 수: %d%n",
fetchJoin.avgMillis(), fetchJoin.avgSqlCount());
System.out.printf("서비스 분리 조회 - 평균 시간: %.2f ms, 평균 SQL 실행 수: %d%n",
separatedLookup.avgMillis(), separatedLookup.avgSqlCount());
assertThat(fetchJoin.avgSqlCount()).isLessThan(separatedLookup.avgSqlCount());
}
결과
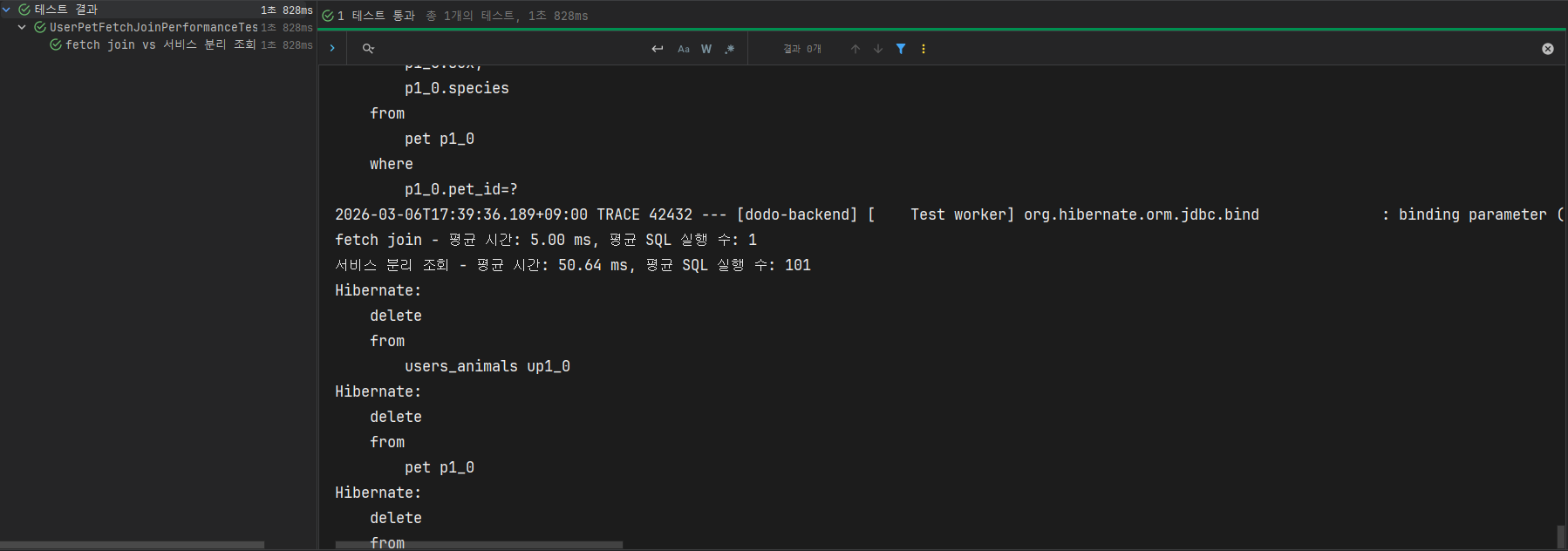
테스트 결과를 보면 Fetch Join 방식은 평균 조회 시간 약 5.00ms, SQL 실행 수 1회로 나타났으며, 서비스 분리 조회 방식은 평균 조회 시간 약 50.64ms, SQL 실행 수 101회로 나타났습니다.
이는 Fetch Join이 연관 엔티티를 처음 조회하는 시점에 함께 가져오기 때문에 추가 조회가 발생하지 않는 반면,
서비스 분리 조회 방식은 필요한 데이터를 각각 다시 조회하는 구조이기 때문입니다. 실제 테스트에서도 반려동물
100건을 기준으로 Fetch Join은 한 번의 쿼리로 모든 데이터를 가져온 반면, 서비스 분리 조회 방식은
petId 조회 1번 + Pet 조회 100번이 실행되면서 총 101번의 SQL이 발생했습니다.
즉 조회 대상이 많아질수록 두 방식의 차이는 더 크게 나타날 수 있으며, 특히 목록 조회처럼 여러 개의 연관 데이터를
함께 사용하는 상황에서는 Fetch Join 방식이 훨씬 효율적일 수 있지만 반대로 서비스 분리 조회 방식은 쿼리 수만 보면 불리할 수 있지만, 각 도메인의 책임을 명확하게 나누고 서비스 간 의존성을 관리하기에는 더 유리한 구조입니다.
결국 조회 성능이 중요한 경우에는 Fetch Join, 도메인 책임 분리가 중요한 경우에는 서비스 계층에서 데이터를
조합하는 방식을 선택하는 것이 적절하다고 볼 수 있습니다.
마무리
JPA에서 연관 데이터를 조회하는 방식을 정리하면서 느낀 핵심을 다시 정리해보면 다음과 같습니다.
Fetch Join은 연관된 엔티티를 한 번의 쿼리로 함께 조회하여N+1문제를 줄이고 조회 성능을 개선하기 위한
방법이라는 점을 이해하게 되었습니다.- 서비스 계층에서 조회를 조합하는 방식은 쿼리 횟수는 늘어날 수 있지만, 도메인 책임을 분리하고 구조를 더
유연하게 가져갈 수 있다는 장점이 있습니다. - 결국 어떤 방식이 더 좋다고 단정하기보다 조회 성능과 도메인 구조 사이에서 어떤 기준을 우선할지 판단하는 것이 더 중요하다고 느꼈습니다.