JPA
JPA에 대해서 적어봤습니다.

주제 선정 이유
JDBC와 MyBatis를 통해 데이터 중심의 개발 방식을 경험하다 보면 SQL을 직접 작성하고 제어하는 데에는
익숙해지지만, 점차 자바의 핵심인 객체지향 패러다임을 유지하면서 데이터를 다루는 방식에 대한 고민이 됩니다.
반복되는 CRUD 쿼리 작성과 객체 모델과 관계형 데이터베이스 사이의 차이로 인해 코드가 점점 복잡해지고, 데이터 접근 로직과 비즈니스 로직이 섞이면서 구조를 한눈에 파악하기 어려워지는 상황을 경험하게 되는데 이때 기존 SQL 중심
방식은 동작을 명확하게 제어할 수 있다는 장점이 있지만, 로직이 커질수록 객체와 데이터 사이의 간극을 계속해서 수동으로 맞춰야 하는 부담이 생기게 되며, 이를 더 자연스럽게 해결할 수 있는 방법은 없을까라는 고민이 들게 됩니다.
그래서 이번 글에서는 JPA를 중심으로 객체와 데이터베이스를 매핑하는 방식과 영속성 컨텍스트, 지연 로딩과 같은 핵심 개념을 살펴보면서, 객체지향적인 데이터 처리 방식이 어떻게 코드의 구조를 개선하고 더 안정적인 데이터 레이어를 만들어주는지에 대해 정리해보고자 합니다.
JPA가 뭘까?
JPA(Java Persistence API)는 객체와 관계형 DB를 연결하는 자바의 표준 ORM(Object-Relational Mapping)기술이며 하이버네이트가 JPA의 대표적인 구현체이고 자바의 객체를 데이터베이스에 저장하는것처럼 동작하도록 도와준다.
편해진 점
1
2
3
4
5
String sql = "update item " +
"set item_name=:itemName, price=:price, quantity=:quantity " +
"where id=:id";
template.update(sql, param);
JDBC에서는 쿼리를 붙여서 사용해야 했던 반면에 JPA에서는
1
2
3
Item item = em.find(Item.class, id);
item.setItemName(newName);
item.setPrice(newPrice);
객체의 값을 바꾸는 행위 그 자체를 데이터베이스에 반영하기 때문에 수정 쿼리를 고민할 필요가 없습니다.
1
2
3
4
5
6
7
8
String sql = "select id, item_name, price, quantity from item";
if (StringUtils.hasText(itemName)) {
sql += " where item_name like concat('%',:itemName,'%')";
}
if (maxPrice != null) {
sql += " and price <= :maxPrice";
}
그리고 이런식으로 JDBC에서는 동적 쿼리를 작성해야 했던 반면에 JPA에서는
1
2
3
4
5
6
String jpql = "select i from Item i where i.itemName like :itemName and i.price <= :maxPrice";
List<Item> result = em.createQuery(jpql, Item.class)
.setParameter("itemName", "%" + itemName + "%")
.setParameter("maxPrice", maxPrice)
.getResultList();
이런식으로 엔티티 객체를 대상으로 쿼리하는 JPQL를 사용하여, 동적 쿼리 상황에서도 훨씬 정돈된 코드를 유지합니다.
구성요소
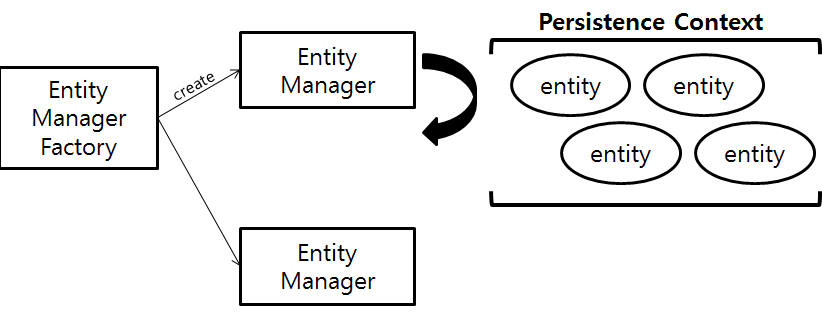
JPA가 어떻게 SQL을 처리하는지 이해하려면, 세 가지 객체의 역할을 알아야 합니다.
EntityManagerFactory
EntityManager를 찍어내는 공장인데 데이터베이스 하나만 생성되어 애플리케이션 실행부터 종료 시점까지 유지되며 생성 비용이 매우 크기 때문에 딱 한 번만 만들어 공유하며, 데이터베이스 연결 정보와 엔티티 매핑 정보를 모두 쥐고 있는 핵심 저장소입니다.
EntityManager
실제 엔티티를 저장, 수정, 조회하는 일용직 작업자인데 팩토리로부터 생성되어 하나의 트랜잭션이나 요청을 처리한 뒤에는 반드시 소멸되어야 하고 내부적으로 영속성 컨텍스트라는 개인 작업 공간을 가지고 있어, 객체를 효율적으로
관리합니다.
Persistence Context
엔티티를 영구 저장하는 환경이라는 뜻으로, 일용직 작업자(EntityManager)가 일을 할 때 사용하는 전용 작업대이며
고객의 요청이 올 때마다 생성된 작업자는 이 공간에 객체를 올려두고 관리합니다.
설정
순수 스프링에서 JPA를 설정 해보겠습니다.
gradle
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
plugins {
id 'java'
}
group = 'java-basic'
version = '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
// JPA 하이버네이트 (Entity Manager 포함)
implementation 'org.hibernate:hibernate-entitymanager:5.3.10.Final'
// H2 데이터베이스
implementation 'com.h2database:h2:1.4.199'
// javax.xml.bind (Java 9 이상에서 JPA 사용 시 필수 라이브러리)
implementation 'javax.xml.bind:jaxb-api:2.3.1'
}
test {
useJUnitPlatform()
}
여기서 DB Dialect라고 있는데 이것의 기능은 추상화된 JPA 기능을 DB마다 다른 문법으로 지원해주는 API입니다.
application.properties
1
2
3
4
5
6
7
8
9
10
11
# DB 연결 정보
jpa.db.driver-class-name=org.h2.Driver
jpa.db.url=jdbc:h2:tcp://localhost/~/test
jpa.db.username=sa
jpa.db.password=
# 하이버네이트 상세 설정
jpa.hibernate.dialect=org.hibernate.dialect.H2Dialect
jpa.hibernate.show_sql=true
jpa.hibernate.format_sql=true
jpa.hibernate.use_sql_comments=true
JpaConfig
application.properties의 값을 @value로 읽어와서 빈(Bean)을 생성합니다.
- 선택
- Maven 환경에서는 관습적으로
persistence.xml을 작성해야 하고, Gradle 환경에서도 동일하게 XML 작성이 가능합니다. - 하지만 순수
Spring에Gradle환경이라면 저는Java Config방식을 선호하는데 별도의xml파일 관리 없이
자바 코드 내에서 설정을 직관적으로 제어할 수 있고, 컴파일 시점에 오류를 확인할 수 있어 유지보수 측면에서 훨씬 유리하기 때문입니다.
- Maven 환경에서는 관습적으로
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
@Configuration
@EnableTransactionManagement
public class JpaConfig {
@Value("${jpa.db.url}") private String url;
@Value("${jpa.db.username}") private String username;
@Value("${jpa.db.password}") private String password;
@Value("${jpa.db.driver-class-name}") private String driverClassName;
@Value("${jpa.hibernate.dialect}") private String dialect;
// DB 접속 정보
@Bean
public DataSource dataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName(driverClassName);
dataSource.setUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
return dataSource;
}
// 엔티티 매니저 팩토리
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory() {
LocalContainerEntityManagerFactoryBean em = new LocalContainerEntityManagerFactoryBean();
em.setDataSource(dataSource());
// 엔티티(@Entity) 클래스가 위치한 패키지 경로
em.setPackagesToScan("com.example.jpa.entity");
HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();
em.setJpaVendorAdapter(vendorAdapter);
// 하이버네이트 세부 설정 주입
Map<String, Object> properties = new HashMap<>();
properties.put("hibernate.dialect", dialect);
properties.put("hibernate.show_sql", "true");
properties.put("hibernate.format_sql", "true");
em.setJpaPropertyMap(properties);
return em;
}
// 트랜잭션 매니저
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory emf) {
JpaTransactionManager transactionManager = new JpaTransactionManager();
transactionManager.setEntityManagerFactory(emf);
return transactionManager;
}
}
이렇게 하면 xml 없이도 가동이 가능합니다.
그래서 어떻게 쓰라고?

이제 설정한 구조에 맞춰 실제 코드를 어떻게 작성하는지 살펴보겠습니다.
엔티티와 테이블 매핑
1
2
3
4
5
6
7
8
9
10
11
12
@Entity
@Table(name = "USER") // @Table 어노테이션으로 직접 테이블 이름 지정 가능(옵션, 비추천)
public class Member { // final/inner 클래스, enum, interface 클래스 사용 불가
@Id // PK 매핑
private Long id; // 저장할 필드에 final 사용 불가
@Column(name = "USER_NAME") // 컬럼명 지정 가능(옵션)
private String name;
public Member() {} // 기본 생성자 필수
}
테이블과 1:1 매핑되는 객체를 엔티티라고 하며 @Entity 어노테이션으로 지정하고 테이블은 자동으로 지정하고 기본적으로 JPA 내부에서 사용하는 엔티티 이름은 클래스 이름이랑 같고, 테이블 이름도 클래스 이름으로 자동 매핑되기
때문에 이름을 바꾸는거는 비 추천합니다.
Order의 경우DB예약어라Order엔티티 테이블 이름을Orders로 변경해야합니다.1
org.hibernate.exception.SQLGrammarException: could not execute statement Caused by: org.h2.jdbc.JdbcSQLSyntaxErrorException: Syntax error in SQL statement "INSERT INTO ORDER ..."; expected "identifier";
필드와 컬럼 매핑
| 어노테이션 | 설명 |
|---|---|
@Column | 컬럼 매핑 |
@Temporal | 날짜 타입 매핑(자바 1.8부터 나온 LocalDateTime을 쓰면 생략 가능) |
@Enumerated | enum 타입 매핑(value 속성 Enum.Type.STRING 필수 사용) |
@Lob | BLOB, CLOB 매핑 |
@Transient | 특정 필드를 컬럼에 매핑하지 않음(매핑 무시) |
@Lob은 DB의 일반적인 문자 제한을 넘어서는 아주 긴 텍스트나 바이너리 데이터를 지정할 때 사용하고 매핑 규칙은
필드 타입에 따라 DB 타입이 자동으로 결정됩니다.
- 문자열
CLOB으로 매핑한다. - 바이너리(
byte[])는BLOB으로 매핑한다.
기본키 테이블 매핑
직접 할당할 때는 @Id만 사용하면 되지만, 번호가 자동으로 생성되길 원한다면 @GeneratedValue의 전략(strategy)를 설정해야 합니다.
| 전략 | 핵심 특징 | 주요 DB | 비고 |
|---|---|---|---|
AUTO | 방언에 따라 자동으로 지정(기본값) | 전체 | DB가 바뀌어도 유연하게 대응 가능 |
IDENTITY | 기본키 생성을 DB에 위임 | MySQL, PostgreSQL | em.persist() 시점에 즉시 INSERT 실행 |
SEQUENCE | DB 시퀀스 오브젝트 사용 | Oracle, H2 | allocationSize를 통한 성능 최적화 가능 |
TABLE | 키 생성 전용 테이블 사용 | 모든 DB | 모든 DB 적용 가능하나 성능이 낮음 |
IDENTITY 전략은 데이터베이스에 값을 넣어야만 PK 값을 알 수 있는 방식입니다.
- 특징
JPA는 영속성 컨텍스트에서 객체를 관리하려면 무조건PK가 필요한데,IDENTITY는DB에 들어가야PK가 생깁니다.
- 동작
- 따라서
em.persist()를 호출하는 즉시DB에INSERT쿼리를 날려서PK를 받아옵니다.
- 따라서
SEQUENCE 전략은 DB 시퀀스 기능을 사용해서 PK를 생성합니다.
- 최적화
allocationSize를 설정하면 한 번 호출에 여러 개의 시퀀스를 메모리에 미리 할당받아, 매번DB를 호출하는 성능 저하를 막을 수 있습니다.
1 2 3 4 5 6 7 8 9 10
@Entity @SequenceGenerator( name = "MEMBER_SEQ_GENERATOR", sequenceName = "MEMBER_SEQ", initialValue = 1, allocationSize = 50) // 50개씩 미리 땡겨옴 public class Member { @Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "MEMBER_SEQ_GENERATOR") private Long id; }
EntityManager 사용법
이제 실제 일용직 작업자(EntityManager)를 고용해서 데이터를 다뤄보겠습니다.
스프링 없이 직접 사용
스프링이 자동으로 해주는 일을 코드로 풀어보면 다음과 같은데 JPA의 모든 데이터 변경은 반드시 트랜잭션 안에서 실행되어야 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class JpaMain {
public static void main(String[] args) {
// 공장 세우기
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
// 작업자 고용
EntityManager em = emf.createEntityManager();
// 트랜잭션 시작
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
Member member = new Member();
member.setId(2L);
member.setName("helloB");
em.persist(member); // 영속성 컨텍스트에 저장
tx.commit(); // 커밋 시점에 실제 DB로 SQL 전송
} catch (Exception e) {
tx.rollback(); // 에러 발생 시 롤백
} finally {
em.close(); // 작업 종료 후 작업자 소멸
}
emf.close(); // 앱 종료 시 공장 폐쇄
}
}
EntityManagerFactory는 애플리케이션 전체에서 딱 하나만 생성해서 공유하고 EntityManager는 쓰레드 간에 절대
공유하면 안되며, 사용 후 반드시 버려져야 합니다.
| 기능 | 코드 | 설명 |
|---|---|---|
| 삽입 | em.persist(entity) | 엔티티를 영속성 컨텍스트에 저장합니다. |
| 조회 | em.find(Class, id) | PK를 기준으로 엔티티를 찾습니다. |
| 삭제 | em.remove(entity) | 해당 엔티티를 DB에서 삭제하기 위해 마크합니다. |
| 수정 | foundMember.setName("...") | 별도 메서드 없음. 객체 값만 바꾸면 자동 수정됩니다. |
| 플러시 | em.flush() | 쌓여있는 SQL을 DB에 즉시 전송합니다. |
| 준영속 | em.detach(entity) | 특정 엔티티를 영속성 컨텍스트에서 분리합니다. |
| 초기화 | em.clear() | 영속성 컨텍스트의 모든 엔티티를 비웁니다. |
영속성 컨택스트와 엔티티 생명주기
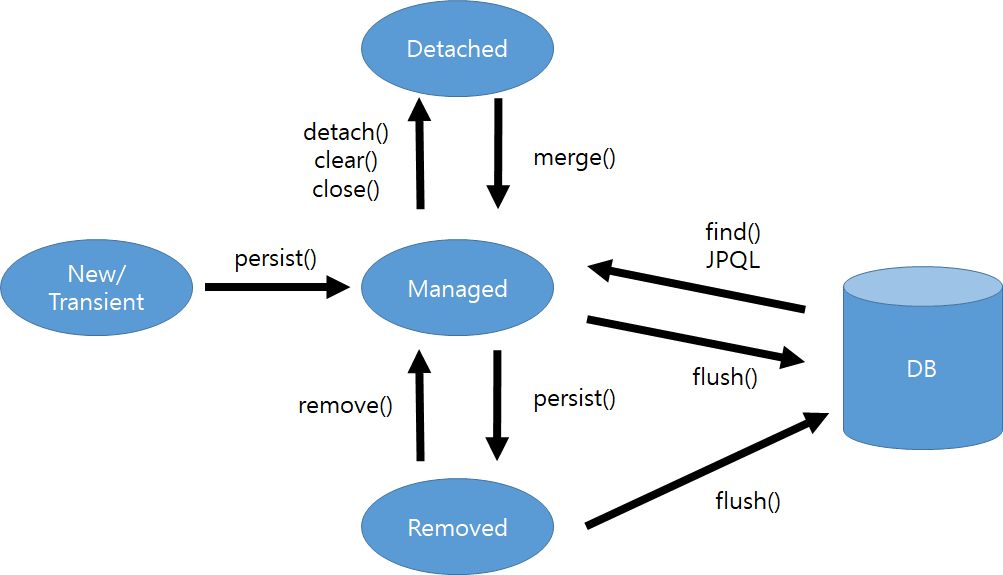
가장 중요한 것은 내 객체가 지금 어떤 상태인가를 파악하는 것입니다.
- 비영속 (
new/transient)- 객체만 생성한 상태, 아직
JPA와는 아무런 관계가 없다.
- 객체만 생성한 상태, 아직
- 영속 (
managed)em.persist()를 통해 영속성 컨택스트에 저장된 상태, 이제JPA의 관리를 받습니다.
- 준영속 (
detached)- 영속성 컨택스트에 있다가 분리된 상태, 더 이상
JPA가 관리하지 않습니다.
- 영속성 컨택스트에 있다가 분리된 상태, 더 이상
- 삭제 (
removed)- 실제
DB삭제를 요청한 상태입니다.
- 실제
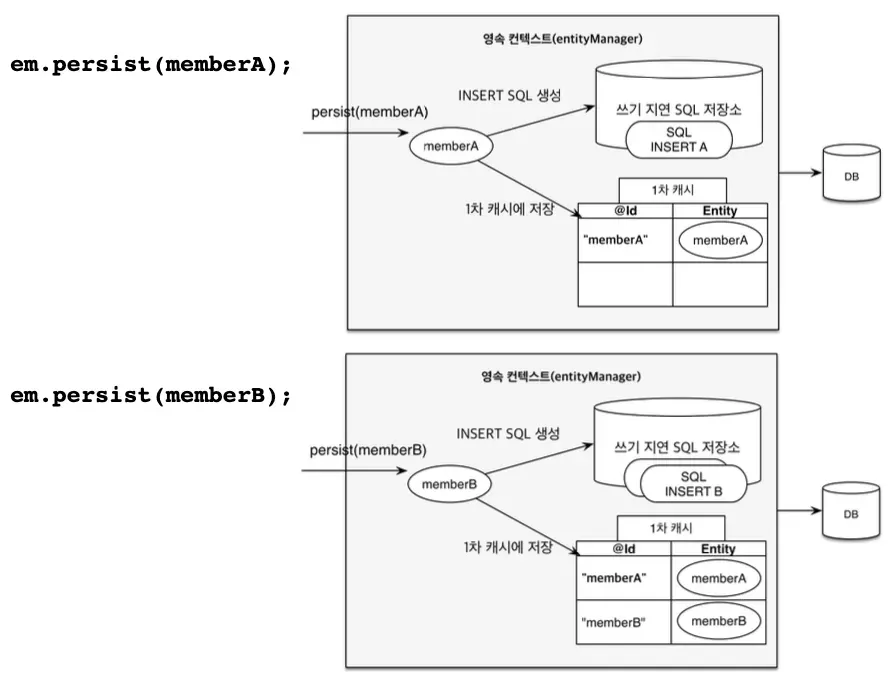
영속성 컨택스트를 거쳐야하는데는 이유가 있는데 그 이유는 작업자(EntityManager)가 전용 작업대
(Persistence Context) 위에서 엔티티를 관리합니다.
- 1차 캐시
- 똑같은
ID를 가진 객체를 두 번 조회하면, 두 번째는DB를 가지 않고 메모리(작업대)에서 바로 꺼내줍니다.
- 똑같은
DirtyChecking- 우리가 객체 값만 바꿔도
JPA가 스냅샷과 비교해서 알아서update쿼리를 만들어줍니다.
- 우리가 객체 값만 바꿔도
- 쓰기 지연
persist()할 때마다DB에 가는 게 아니라, 커밋 직전에SQL저장소에 모아둔 쿼리를 한번에 보냅니다.
DB 스키마 자동 생성
JPA는 엔티티 정보를 바탕으로 애플리케이션을 실행한 시점에 DDL(CREATE, ALTER 등)을 자동으로 생성해주는 편리한 기능을 제공합니다.
1
spring.jpa.hibernate.ddl-auto=?
| 옵션 | 설명 | 주의사항 |
|---|---|---|
create | 기존 테이블 삭제 후 생성 | 운영 서버 절대 사용 금지 |
create-drop | 생성 후 종료 시점에 삭제 | 테스트 환경에서 사용 |
update | 변경된 부분만 반영 | 컬럼 삭제는 안 됨 |
validate | 엔티티-테이블 매핑 검증만 수행 | 운영 환경 권장 |
none | 사용 안 함 | 기본값 |
상속관계 매핑
객체는 참조를 사용하고 DB는 외래키(FK)를 사용하는데 이 둘을 연결하는 것이 연관관계 매핑입니다.
다대일 (@ManyToOne)
가장 많이 사용하는 연관관계 입니다.
- 단방향
- 외래 키가 있는 곳에
@JoinColumn을 선언합니다.
- 외래 키가 있는 곳에
- 양방향
- 반대편 엔티티에
mappedBy를 설정하여 읽기 전용 권한만 줍니다.
- 반대편 엔티티에
다대다 (@ManyToMany)
왠만하면 사용 금지입니다.
- 관계형
DB는 다대다를 테이블 2개로 표현할 수 없어 중간 테이블이 필요합니다. - 연결 테이블을 엔티티로 승격시켜
@OneToMany,@ManyToOne으로 풀어내야 합니다.
전략
객체의 상속 구조를 DB의 테이블로 표현하는 전략이며 @Inheritance(strategy=InheritanceType.XXX)태그를 엔티티 클래스에 부착합니다.
SINGLE_TABLE

한테이블에 모든 필드를 다 넣는다고 생각하면 되고 조회 성능이 빠르고 단순할 때 추천합니다.
JOINED
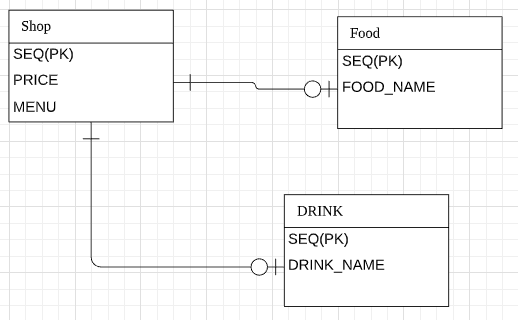
각각 테이블로 만들고 조인으로 조회한다고 생각하면 되고 이 전략은 가장 정석적이면서 정교합니다.
TABLE_PER_CLASS
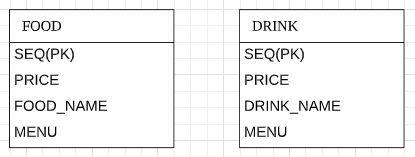
엔티티 마다 각자의 테이블을 만드는 전략입니다.
MappedSuperclass
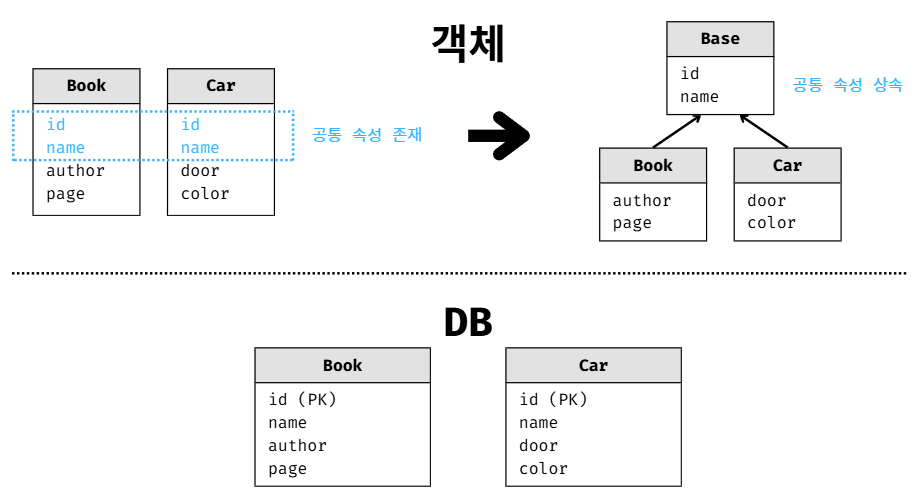
상속은 아니지만 id, name 같은 공통 속성만 내려받고 싶을때 사용합니다.
프록시와 지연 로딩
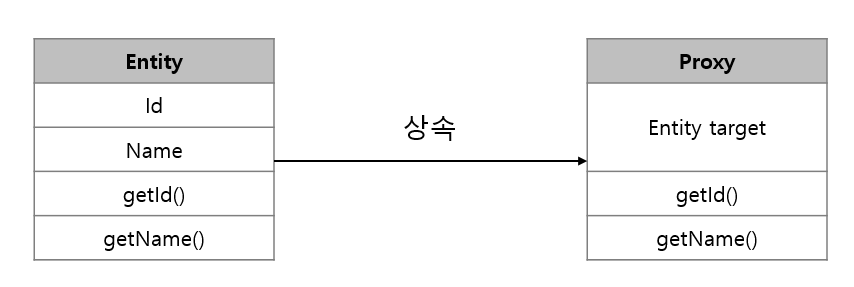
JPA 성능 최적화의 핵심은 필요할때만 DB에서 가져오는것입니다.
지연로딩 (LAZY)
@ManyToOne(fetch = FetchType.LAZY)
- 연관된 엔티티를 실제 사용하는 시점에 쿼리가 나갑니다.
- 프록시
- 실제 객체 대신 가짜 객체를 넣어뒀다가, 메서드 호출 시점에 실제
DB를 조회합니다.1 2 3
@ManyToOne(fetch = FetchType.LAZY) // 지연로딩, 즉시로딩은 EAGER @JoinColumn(name = "TEAM_ID") private Team team;
- 실제 객체 대신 가짜 객체를 넣어뒀다가, 메서드 호출 시점에 실제
N + 1 문제
- 즉시 로딩(
EAGER)를 쓰면 1개를 조회했는데 연관된 데이터를 가져오기 위해서 N개의 쿼리가 더 나가는 대참사가 발생합니다. - 무조건 지연 로딩(
LAZY)를 기본으로 사용하고, 성능 최적화가 필요하면fetch join을 사용한다.
영속성 전이 (CASCADE)와 고아 객체
부모 엔티티를 관리할 때 연관된 자식 엔티티들을 어떻게 함께 처리할지에 대한 설정입니다.
| 옵션 | 종류 |
|---|---|
ALL | 모두 적용 |
PERSIST | 영속 - 안전하게 저장만 할 때 |
REMOVE | 삭제 |
MERGE | 병합 |
REFREST | REFRESH |
DETACH | DETACH |
CASCADE는 부모가 사라질 때 자식도 같이 사라진다고 생각하면 됩니다.
- 부모를 저장(
persist)할 때 자식도 자동으로 저장되게 하고 싶을 때 사용합니다 (보통ALL,PERSIST선언)1 2
@OneToMany(mappedBy = "team", cascade = CascadeType.PERSIST) private List<Member> members = new ArrayList<>();
고아 객체(orphanRemoval)은 부모와 연결이 끝긴 자식은 삭제한다고 생각하면 됩니다.
- 부모의 컬렉션에서 자식을 제거하면,
DB에서도 해당 데이터가 삭제되는 기능입니다.
값 타입
JPA의 값 데이터 타입은 임베디드 타입과 값 타입으로 나뉩니다.
임베디드 타입
@Embeddable은 City, Street, Zipcode를 묶어 Address라는 클래스로 만드는 것처럼, 기본 타입들을 모아 의미 있는 객체로 만드는 도구입니다.
1
2
3
4
5
6
7
8
9
10
@Embeddable
public class Address {
private String city;
private String street;
private String zipcode;
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "MY_POSTMAN_PK", insertable = false, updatable = false)
private PostMan postMan;
}
1
2
3
4
5
6
7
8
9
10
11
12
@Entity
public class Member {
@Embedded
@AttributeOverrides({
@AttributeOverride(
name="city", column = @Column(name = "WORK_CITY")),
@AttributeOverride(
name="street", column = @Column(name = "WORK_STREET")),
@AttributeOverride(
name="zipcode", column = @Column(name = "WORK_ZIPCODE")) })
private Address workAddress;
}
값 타입 컬렉션
값 타입을 리스트(List)로 들고 있는 형태이며 식별자가 없어 변경이 어렵기 때문에, 데이터가 많아지면 엔티티로 승격시키는것을 권장합니다.
1
2
3
4
5
6
7
8
9
10
11
12
@ElementCollection
@CollectionTable(name = "FAVORITE_FOOD", joinColumns =
@JoinColumn(name = "MEMBER_ID")
)
@Column(name = "FOOD_NAME")
private Set<String> favoriteFoods = new HashSet<>();
@ElementCollection
@CollectionTable(name = "ADDRESS_HISTORY", joinColumns =
@JoinColumn(name = "MEMBER_ID")
)
private List<Address> addressHistory = new ArrayList<>();
JPQL (Java Persistence Query Language)
JPA의 성능 최적화의 핵심입니다.
특징
테이블이 아닌 엔티티 객체 대상으로 쿼리하며 방언(Dialect) 설정에 따라 적절한 SQL로 변환되어 DB로 전송됩니다.
패치 조인(Fetch Join)
지연로딩 (LAZY)를 사용하면 발생하는 N+1 문제를 해결하는 유일한 정석 방법입니다.
1
2
-- 패치 조인: 한 번의 쿼리로 팀과 멤버를 한꺼번에 다 가져옴!
select t from Team t join fetch t.members
한계점
- 페이징 API(
setFirstResult,setMaxResults)를 사용할 수 없는데 이유는 데이터가 뻥튀기되어 메모리 과부하가 발생할 수 있기 때문입니다.- 이때
batch_size설정을 통해 성능을 타협하는 것이 정석입니다.
- 이때
벌크연산
JPA의 수정 방식인 변경 감지는 엔티티를 하나씩 조회해서 값을 바꾸면 쿼리가 엔티티 개수만큼 나가는데 만약 1,000명의 회원 급여를 한 번에 인상해야 한다면 1,000번의 UPDATE 문이 실행되는 비효율이 발생하는데 이때 한 번의 쿼리로 여러 레코드를 수정하거나 삭제하는 기능이 바로 벌크 연산입니다.
1
2
int resultCount = em.createQuery("update Member m set m.age = 20")
.executeUpdate();
근데 이 벌크연산의 문제점은 영속성 컨텍스트를 완전히 무시하고 데이터베이스에 직접 쿼리를 날리기 때문에 영속성
컨텍스트에 있는 객체와 DB의 실제 데이터가 달라지는 데이터 불일치 문제가 발생할 수 있습니다.
- 해결법
- 영속성 컨택스트에 아무것도 없을때 벌크 연산을 가장 먼저 실행하고 연산을 한 뒤 컨택스트를 초기화합니다.
- 만약 컨텍스트에 엔티티가 이미 있다면, 벌크 연산 직후에 반드시
em.clear()를 호출하여 초기화해야 다음 조회 시DB에서 수정된 데이터를 다시 읽어옵니다.
- 만약 컨텍스트에 엔티티가 이미 있다면, 벌크 연산 직후에 반드시
- 영속성 컨택스트에 아무것도 없을때 벌크 연산을 가장 먼저 실행하고 연산을 한 뒤 컨택스트를 초기화합니다.
마무리
JPA의 개념을 한 바퀴 돌아보며, 제가 느낀 핵심을 다시 정리해보면 다음과 같습니다.
SQL중심의 반복적인 노가다를 벗어나, 자바의 본질인 객체지향 설계에만 집중하면서도 데이터를 자유자재로
다룰 수 있게 합니다.- 1차 캐시, 쓰기 지연, 변경 감지라는 메커니즘을 통해 단순한 쿼리 실행기 그 이상의 성능 최적화와 데이터 정합성을 제공합니다.
- 복잡한 테이블 간의 관계를 객체 참조로 매핑하고, 지연 로딩 (
LAZY)과 페치 조인(Fetch Join)을 통해N+1문제를 해결합니다. JPA는 강력한 도구이지만, 내부 동작 원리를 모른 채 사용하면 성능 폭탄을 맞을 수 있기 때문에 편리함에 매몰되지 않고 기본기를 다지는 것이 무엇보다 중요합니다.