InnoDB
InnoDB에 대해서 적어봤습니다.

주제 선정 이유
백엔드 개발을 진행하면서 MySQL을 사용하다 보면, 쿼리를 작성하고 결과를 확인하는 과정에는 익숙해지지만 데이터가 실제로 어떻게 저장되고 처리되는지에 대해서는 깊게 고민하지 않는 경우가 많은데 EXPLAIN을 통해 실행 계획을
확인하고 인덱스를 추가하며 성능이 개선되는 경험을 하기도 하지만, 그 변화가 내부적으로 어떤 구조와 원리에 의해
발생하는지까지는 명확히 이해하지 못한 채 넘어가게 됩니다.
처음에는 단순히 인덱스를 추가하면 조회 속도가 빨라진다는 정도로만 받아들이기 쉽지만, 문득 데이터는 어떤 구조로 저장되어 있길래 이런 차이가 발생하는지, 그리고 내가 작성한 SQL이 실제로 어떤 과정을 거쳐 실행되는 것인지에 대한 궁금증이 생기게 됩니다. 특히 MySQL의 기본 스토리지 엔진이 InnoDB라는 사실은 알고 있었지만, 이를 단순히
트랜잭션을 지원하는 엔진 정도로만 이해하고 있었고, 데이터 저장 구조나 읽기 방식, 동시성 처리 방식에 대해서는
명확히 설명하기 어렵다는 점을 깨닫게 되었습니다.
그래서 이번 글에서는 InnoDB가 데이터를 어떤 구조로 저장하고, 어떤 방식으로 읽으며, 이러한 설계가 성능과
동시성에 어떤 영향을 미치는지를 중심으로 살펴보고, 이를 통해 데이터베이스 내부 동작을 정리해보고자 합니다.
InnoDB가 뭘까?
InnoDB는 MySQL에서 기본으로 사용되는 스토리지 엔진이며 MySQL은 단순한 데이터베이스가 아니라, 여러 스토리지 엔진을 선택해서 사용할 수 있는 구조를 가지고 있는데, 그중에서 InnoDB는 현재 가장 널리 사용되는 표준 엔진입니다.
스토리지 엔진
데이터를 실제로 저장하고 읽는 방식을 결정하는 구성 요소이며 우리가 작성하는 SQL은 MySQL 서버 계층에서
처리되지만, 실제로 디스크에 데이터를 저장하고, 인덱스를 관리하고, 트랜잭션을 처리하는 역할은 스토리지 엔진이
담당합니다.
SQL파싱 →MySQL Server Layer- 실제 데이터 저장 및 조회 →
Storage Engine
Clustered Index 구조
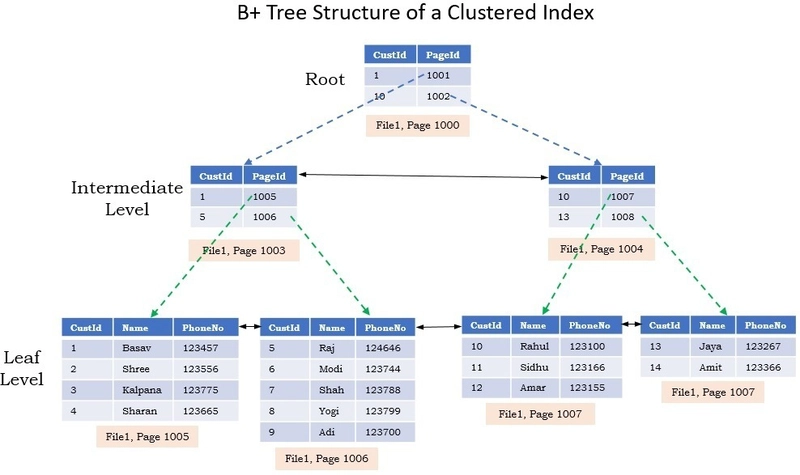
InnoDB의 가장 큰 특징은 Clustered Index 기반 저장 방식이며 테이블 자체가 하나의 B+Tree 구조로 구성되며, Primary Key 기준으로 데이터가 정렬되어 저장됩니다.
Primary Key= 데이터 저장 순서를 결정하는 기준
B+Tree 구조에서 리프 노드에는 실제 데이터가 저장되고 이 구조 때문에 다음과 같은 특징이 생깁니다.
Primary Key조회는 매우 빠름- 범위 조회 (
Between,>,<)에 강함 PK값이 클수록 인덱스 크기도 커짐PK변경 비용이 큼
Secondary Index의 구조
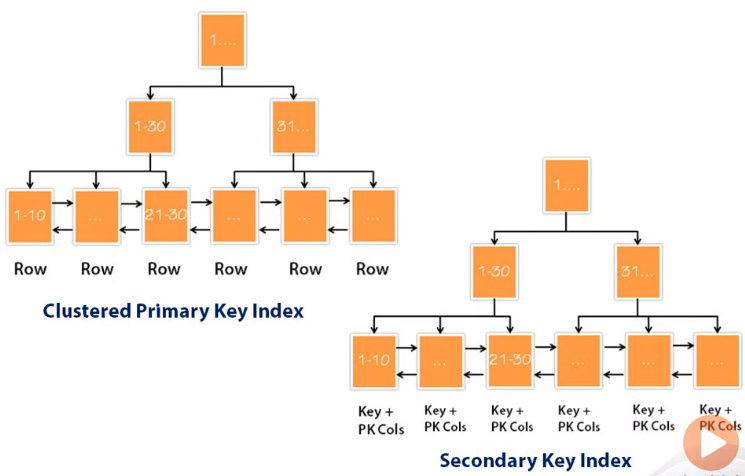
Primary Key가 아닌 컬럼에 인덱스를 생성하면 Secondary Index가 생성되는데 InnoDB에서 Secondary Index는
실제 데이터를 직접 저장하지 않고, 해당 행의 Primary Key 값을 함께 저장하는 구조를 가집니다.
Secondary Index에서 조건에 맞는Primary Key값을 탐색- 해당
Primary Key를 이용해Clustered Index를 다시 탐색 - 실제 데이터를 반환
이와 같은 구조를 통해 InnoDB는 인덱스 일관성을 유지하지만 이 방식은 한 번의 탐색으로 끝나는 것이 아니라 두 번의 B+Tree 탐색이 발생한다는 특징을 가지고 이 구조로 인해서 다음과 같은 특성이 나타납니다.
Primary Key가 길어질수록Secondary Index의 크기도 함께 증가UUID와 같이 긴PK는 전체 인덱스 크기 증가를 유발- 인덱스 개수가 많아질수록 쓰기 비용 증가
- 조회 시
Double Lookup비용 발생 가능
MVCC (Multi Version Concurrency Control)
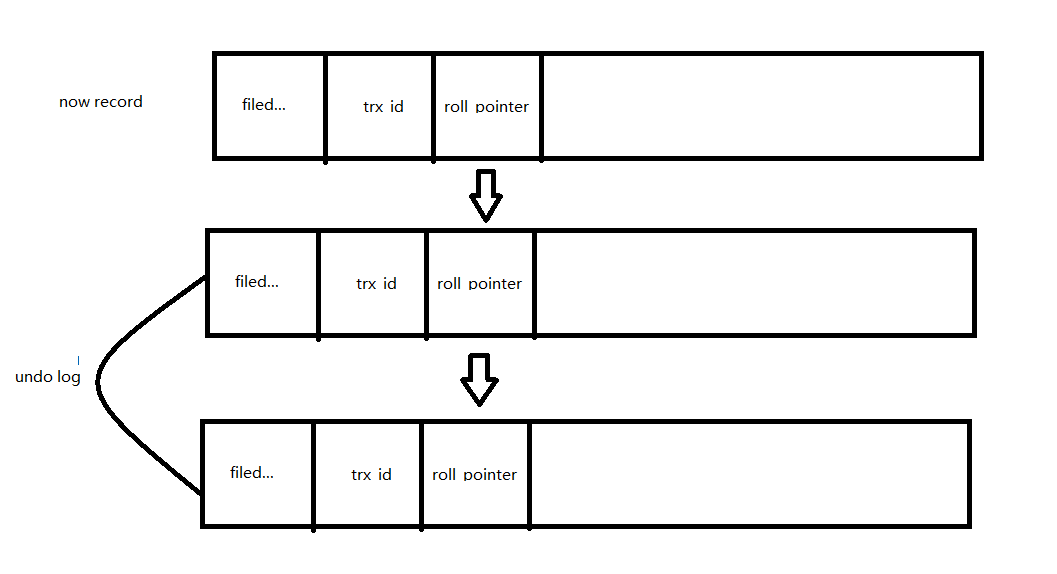
MVCC는 데이터를 한 버전만 유지하는 것이 아니라, 여러 버전을 관리하여 트랜잭션 간 충돌을 최소화하는 방식입니다.
각 행에는 내부적으로 다음과 같은 정보가 함께 저장됩니다.
trx_id: 해당 행을 마지막으로 수정한 트랜잭션IDroll_pointer: 이전 버전을 가리키는 포인터
데이터가 수정되면 기존 값은 Undo Log에 저장되고, 각 트랜잭션은 자신이 시작된 시점에 맞는 데이터 버전을 읽게 되서 다음과 같은 일이 가능하게 됩니다.
SELECT시 락 없이 읽기 가능 (Non-locking Read)- 높은 동시성 유지
- 기본 격리 수준
REPEATABLE READ제공
InnoDB는 단순히 락을 통해 충돌을 제어하는 것이 아니라, 데이터의 여러 버전을 관리함으로써 읽기 성능과 동시성을
동시에 확보합니다.
Redo Log와 Undo Log
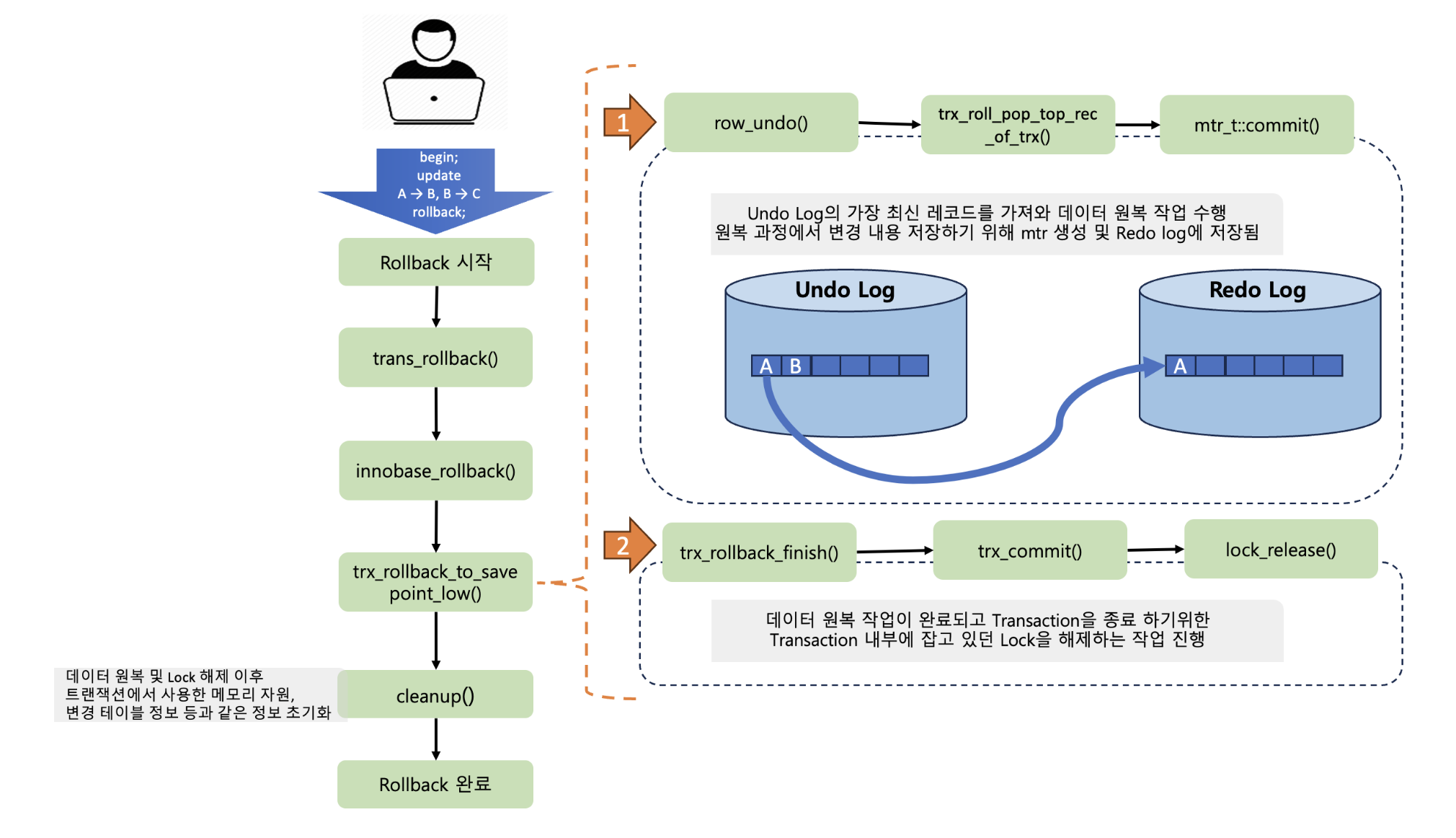
InnoDB는 트랜잭션의 안정성을 보장하기 위해 Redo Log와 Undo Log를 사용합니다.
Redo Log
- 변경 내용을 디스크에 기록
- 서버 장애 발생 시 복구 가능
Durability보장
Undo Log
- 트랜잭션 롤백을 위해 사용
- 이전 데이터 버전 저장
MVCC동작의 기반이 되는 요소Atomicity보장
InnoDB는 WAL (Write-Ahead Logging) 방식을 사용하고 데이터가 디스크에 반영되기 전에 Redo Log를 먼저
기록하는데 이 구조 덕분에 서버가 비정상 종료되더라도 로그를 기반으로 데이터를 복구할 수 있습니다.
그래서 어떻게 쓰라고?

Primary Key는 짧고 단순
InnoDB는 Clustered Index 구조를 사용하기 때문에 Primary Key가 곧 데이터 저장 순서를 결정하고
Secondary Index에는 Primary Key 값이 함께 저장되므로 Primary Key가 길어질수록 모든 보조 인덱스의 크기도
함께 증가합니다.
Auto Increment정수형PK는 공간 효율이 높음UUID와 같이 긴 문자열PK는 인덱스 크기 증가 유발- 랜덤 값
PK는 페이지 분할 가능성 증가
즉, Primary Key는 짧고, 정렬 가능하며, 변경되지 않는 값이 이상적입니다.
인덱스는 적게
인덱스는 조회 성능을 향상시키지만 INSERT, UPDATE, DELETE 시에는 오히려 비용이 증가합니다.
- 데이터 변경 시 모든 관련 인덱스를 함께 수정해야 함
Secondary Index도 함께 업데이트 발생- 페이지 분할 가능성 증가
UUID 성능 영향
UUID는 랜덤 값이기 때문에 Clustered Index의 정렬 구조를 깨뜨립니다.
- 중간 삽입 발생
- 페이지 분할 증가
- 디스크 단편화 가능성 증가
- 캐시 효율 저하
반면 Auto Increment는 항상 마지막 페이지에 삽입되므로 구조적으로 훨씬 안정적입니다.
MVCC 만능은 아니다
MVCC는 읽기 성능과 동시성을 크게 향상시키는 구조이지만, 항상 비용이 없는 것은 아닌데 트랜잭션이 오래 유지될
경우,해당 트랜잭션이 참조하고 있는 이전 버전 데이터는 정리되지 못하고 Undo Log에 계속 남아 있게됩니다.
Undo Log공간 증가Purge작업 지연- 시스템 성능 저하 가능성
따라서 트랜잭션은 가능한 한 짧게 유지하는 것이 InnoDB 구조에 적합한 설계 방식입니다.
마무리
InnoDB를 정리하면서 느낀 핵심을 다시 정리해보면 다음과 같습니다.
Primary Key는 단순한 식별자가 아니라, 데이터 저장 구조 전체를 결정하는 요소라는 점을 이해하게 되었습니다.Secondary Index는 단순한 보조 인덱스가 아니라,Primary Key와 긴밀하게 연결된 구조이며 인덱스 설계는 곧
성능 설계라는 사실을 다시 한번 확인하게 되었습니다.MVCC와Redo/Undo Log구조를 이해하면서, 트랜잭션은 단순히 묶어서 실행하는 기능이 아니라 동시성과
안정성을 동시에 고려한 설계 결과라는 점을 체감하게 되었습니다.