HashMap
HashMap 내부구조에 대해서 적어봤습니다.

주제 선정 이유
코딩 테스트를 준비하면서 다양한 알고리즘 문제를 풀다 보니 HashMap을 사용하는 경우가 굉장히 많았는데, 단순히
값의 존재 여부를 확인하거나 개수를 세는 용도로 자연스럽게 사용하고 있었지만 정작 내부적으로 어떤 방식으로
동작하는지에 대해서는 깊이 고민해본 적이 많지 않았습니다.
특히 시간 복잡도를 고려해야 하는 문제에서 HashMap을 사용하면 평균적으로 O(1)에 가까운 성능을 낼 수 있다는
점은 알고 있었지만, 이 성능이 어떻게 보장되는지, 그리고 해시 충돌이 발생했을 때는 어떤 방식으로 처리되는지에
대해서는 명확하게 설명하기 어려웠고, 문제를 풀면서도 왜 빠른지에 대한 이해 없이 사용하는 경우가 많았습니다.
또한 Java의 HashMap이 내부적으로 LinkedList에서 Tree 구조로 전환된다는 이야기를 접하게 되면서, 단순한
자료구조라고 생각했던 HashMap이 생각보다 더 복잡한 구조를 가지고 있다는 점이 흥미롭게 느껴졌고, 이 기회에 내부
동작 원리를 제대로 정리해보고 싶다는 생각이 들어 이번 글에서 HashMap의 핵심 개념인 해시 함수의 역할부터 충돌
해결 방식(체이닝), Java 8에서의 Tree 구조 변화, 그리고 시간복잡도와 resize 과정까지를 중심으로 내부 동작 원리를 정리해보고자 합니다.
HashMap이 뭘까?
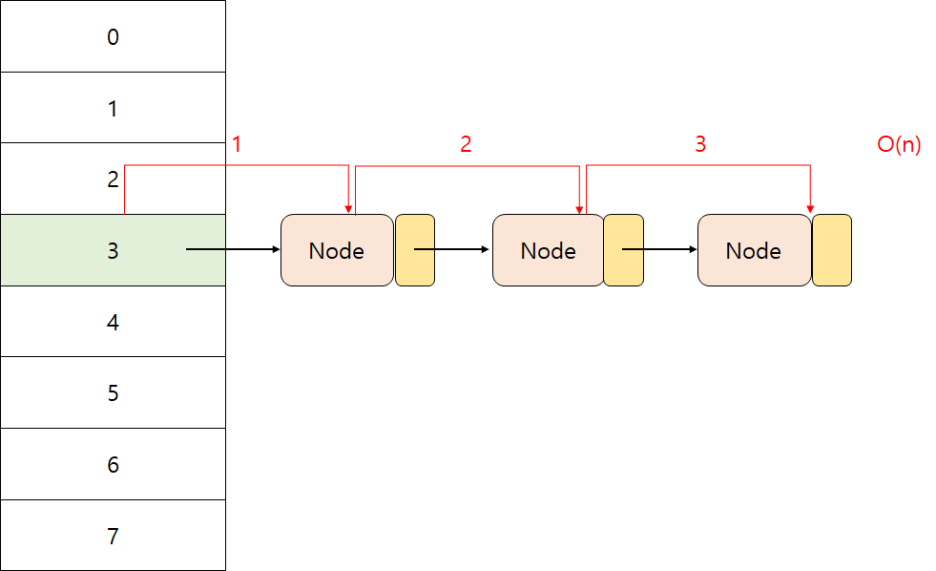
HashMap은 Key-Value 형태로 데이터를 저장하는 자료구조로, 특정 Key를 통해 빠르게 값을 조회할 수 있도록 설계된
컬렉션이고 일반적인 배열이나 리스트는 데이터를 찾기 위해 순차적으로 탐색해야 하기 때문에 최악의 경우 O(N)의
시간이 걸리지만, HashMap은 해시 함수를 이용하여 데이터를 저장할 위치를 바로 계산하기 때문에 평균적으로 O(1)에 가까운 성능으로 조회가 가능합니다.
특징
Key를 통해Value를 조회하는 구조Key는 중복될 수 없고,Value는 중복 가능- 순서를 보장하지 않음
- 평균 시간복잡도
O(1)
기본 구조
내부적으로 배열(Array) 을 기반으로 동작하며, 각 배열의 인덱스를 버킷(bucket) 이라고 부르는데 데이터를 저장할
때는 다음과 같은 흐름으로 동작합니다.
Key의hashCode()를 계산- 해시 값을 기반으로 배열의 인덱스를 결정
- 해당 인덱스에 데이터 저장
즉, HashMap은 단순한 리스트 구조가 아니라 배열 + 해시 함수가 결합된 자료구조라고 볼 수 있습니다.
해시 함수
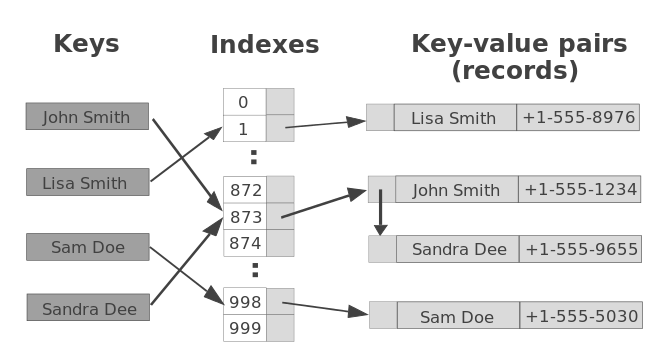
입력된 Key 값을 기반으로 고정된 크기의 정수 값(해시 값)을 만들어내는 역할을 하며, 이 해시 값을 통해 데이터를
저장할 배열의 인덱스를 결정하게 되고 어떤 Key가 들어오더라도 빠르게 위치를 계산해서 바로 접근할 수 있도록
만들어주는 것이 해시 함수의 목적입니다.
중요한 이유
해시 함수는 단순히 값을 변환하는 역할을 넘어서 성능을 결정하는 핵심 요소인데 이론적으로는 모든 데이터가 고르게 분산된다면 항상 O(1)의 성능을 유지할 수 있지만, 실제로는 서로 다른 Key가 같은 인덱스로 매핑되는 경우가
발생하게 됩니다.
이때 특정 버킷에 데이터가 몰리게 되면 탐색 과정이 길어지면서 성능이 저하될 수 있고, 최악의 경우 O(N)까지
떨어질 수 있는데 여기서 해시 함수의 핵심은데이터를 얼마나 균등하게 분산시키느냐에 있으며, 이 분산이 잘
이루어질수록 HashMap의 성능은 안정적으로 유지되지만 아무리 좋은 해시 함수를 사용하더라도 충돌을 완전히 피할 수 없습니다.
이러한 상황을 해시 충돌(Hash Collision)이라고 부릅니다.
충돌 해결 방식
해시 함수를 통해 데이터를 빠르게 저장하고 조회할 수 있지만, 아무리 해시 함수를 잘 설계하더라도 서로 다른 Key가
같은 버킷에 저장되는 해시 충돌은 완전히 피할 수 없어서 이러한 충돌이 발생했을 때 같은 인덱스에 여러 데이터를 저장할 수 있도록 별도의 구조를 사용하여 문제를 해결하게 되는데, 대표적인 방식으로는 체이닝(Chaining)과 개방 주소법(Open Addressing)이 있습니다.
체이닝은 하나의 버킷에 여러 데이터를 연결하여 저장하는 방식이며, 개방 주소법은 충돌이 발생했을 때 다른 빈
인덱스를 찾아 저장하는 방식이기 때문에 각 방식은 구현 방식과 성능 특성이 다르기 때문에 상황에 따라 장단점이
존재하며, 각각의 방법을 살펴보겠습니다.
체이닝(Chaining)
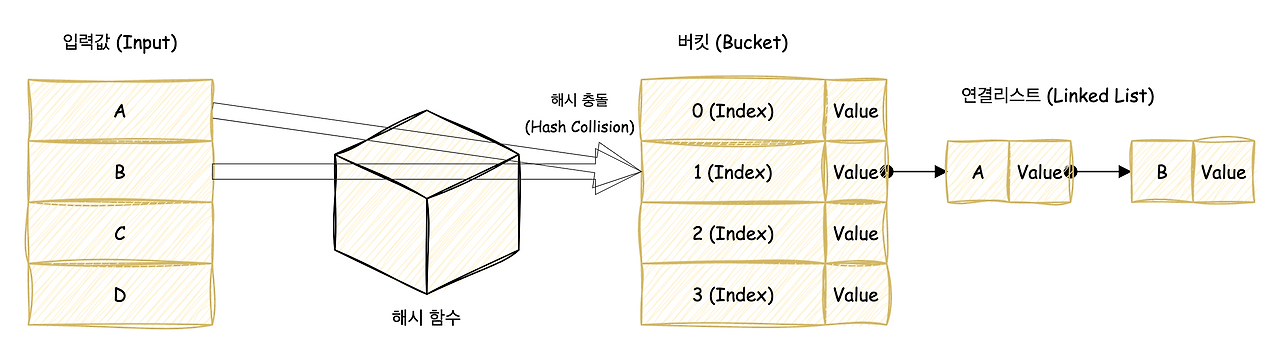
같은 버킷에 충돌한 데이터를 연결 리스트 형태로 저장하는 방식으로, 하나의 인덱스에 여러 개의 데이터가 연결되어
관리됩니다.
- 장점
- 구현이 비교적 단순함
- 테이블이 가득 차도 저장 가능
- 충돌이 발생해도 데이터 손실 없음
- 단점
- 연결 리스트 탐색으로 인해 성능 저하 가능
- 캐시 효율이 떨어짐
- 최악의 경우
O(N)성능
개방 주소법 - 선형 탐사 (Open Addressing - Linear Probing)
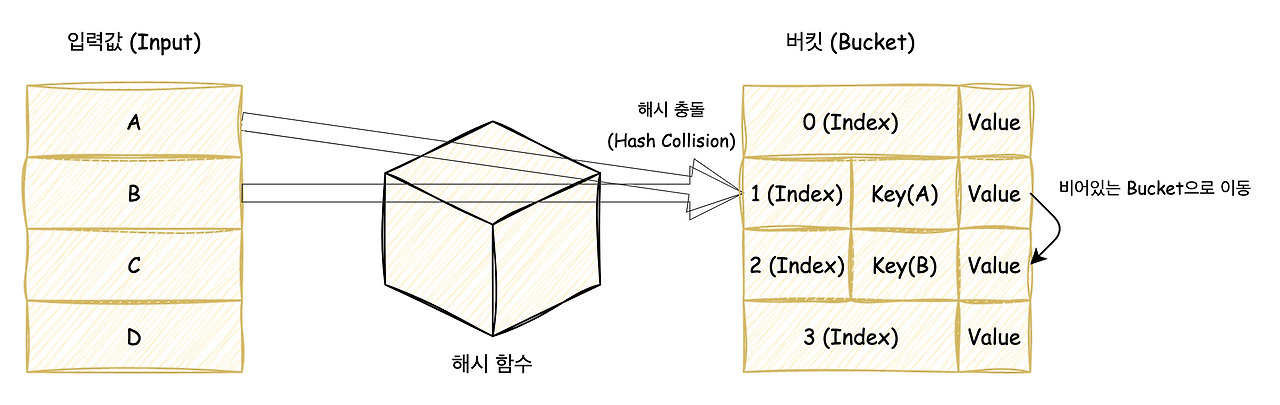
충돌이 발생하면 다음 인덱스를 순차적으로 탐색하면서 빈 공간을 찾아 저장하는 방식입니다.
- 장점
- 추가적인 자료구조 없이 배열만 사용
- 캐시 효율이 좋아 실제 성능이 빠른 경우 많음
- 단점
- 데이터가 몰리는 클러스터링 발생
- 탐색 길어지면 성능 급격히 저하
- 삭제 처리 복잡
개방 주소법 - 이중 해싱 (Open Addressing - Double Hashing)
충돌이 발생했을 때 두 번째 해시 함수를 이용하여 이동 간격을 결정하는 방식입니다.
- 장점
- 클러스터링 문제 완화
- 데이터 분포가 더 균등해짐
- 단점
- 해시 함수가 두 개 필요하여 구현 복잡
- 계산 비용 증가
- 여전히 최악의 경우 성능 저하 가능
Java 8 Tree 구조
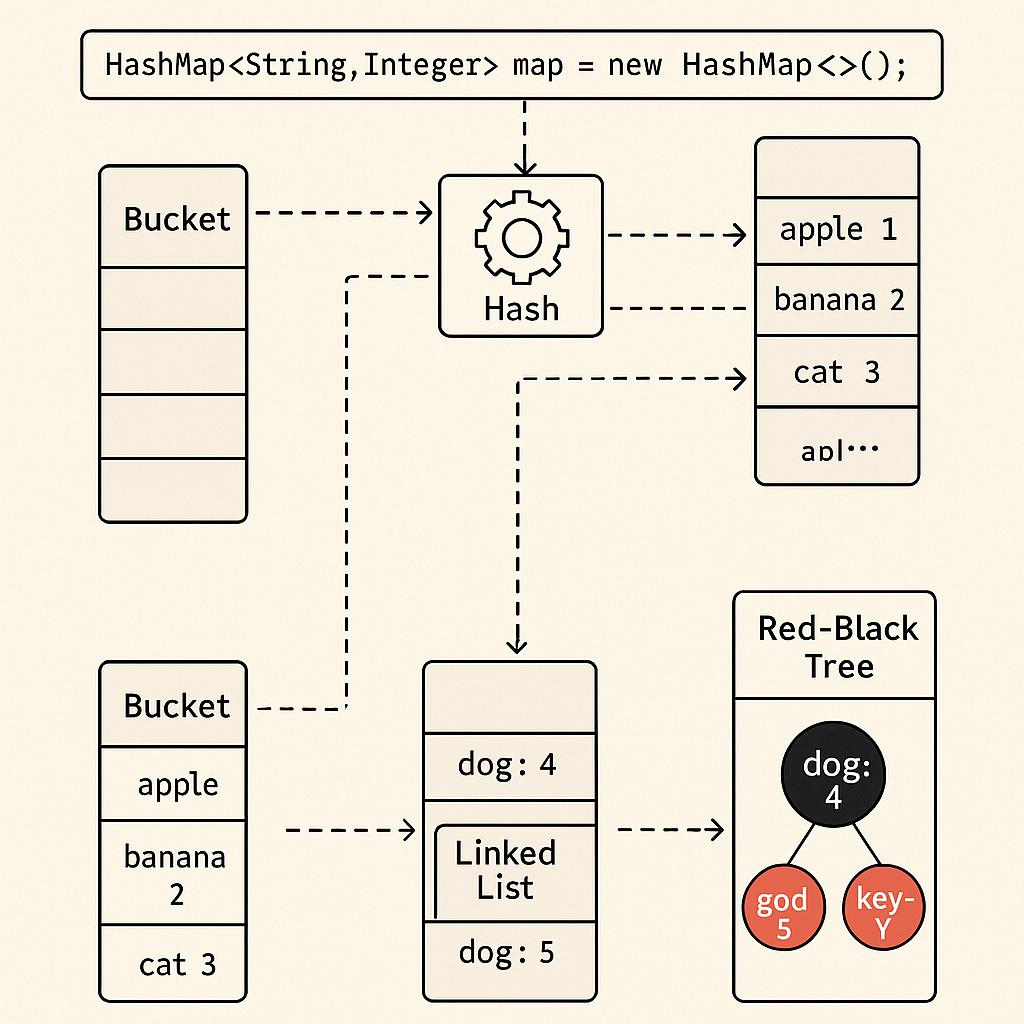
기존 HashMap은 충돌이 발생했을 때 하나의 버킷에 데이터를 LinkedList 형태로 저장하는 체이닝 방식을 사용했는데, 데이터가 많아질 경우 탐색 시간이 길어지면서 성능이 저하되는 문제가 발생할 수 있었고 이러한 문제를 해결하기 위해 Java 8부터는 일정 기준을 넘어서면 LinkedList를 Tree 구조(Red-Black Tree)로 변환하는 방식을 도입하였습니다.
변환 기준
- 버킷의 노드 개수 ≥ 8 이면서 전체 테이블 크기 ≥ 64인 경우 →
Tree로 변환 - 버킷의 노드 개수 ≤ 6 → 다시
LinkedList로 변환
이처럼 일정 개수를 기준으로 구조를 변경함으로써, 데이터가 많아질 경우에도 안정적인 성능을 유지할 수 있도록 설계되었습니다.
Tree로 바뀌는 이유
LinkedList의 경우 탐색 시간이 O(N)이지만, Tree 구조로 변경되면 탐색 시간이 O(log N)으로 줄어들게 되면서
충돌이 많이 발생하는 상황에서도 성능 저하를 최소화할 수 있습니다.
결과적으로 HashMap은 단순한 배열 기반 구조가 아니라 상황에 따라 List와 Tree를 혼합하여 사용하는 구조라고 볼 수 있습니다.
그래서 어떻게 쓰라고?

실제로 내부 구조를 모두 외우기 위해 공부하기보다는, 어떤 상황에서 왜 빠르게 동작하는지 이해하고 적절한 문제에
꺼내 쓸 수 있는 수준으로 익혀두는 것이 중요하다고 생각합니다.
코딩 테스트에서는 특히 값의 존재 여부를 확인해야 하는 경우, 등장 횟수를 세야 하는 경우, 특정 값을 빠르게 찾아야
하는 경우에 HashMap이 매우 자주 등장하는데, 이런 문제를 배열이나 리스트로 처리하면 탐색에 시간이 오래 걸릴 수
있지만 HashMap을 사용하면 평균적으로 더 빠르게 해결할 수 있습니다.
예를 들어 문자열 배열에서 같은 값이 몇 번 나왔는지 세거나, 어떤 숫자가 이미 등장했는지를 즉시 확인하거나, 특정 Key에 대응하는 값을 저장해두고 다시 꺼내와야 하는 상황에서는 HashMap이 거의 정석처럼 사용됩니다.
1
2
3
4
5
Map<String, Integer> map = new HashMap<>();
for (String word : words) {
map.put(word, map.getOrDefault(word, 0) + 1);
}
위와 같이 사용하면 각 문자열의 등장 횟수를 손쉽게 저장할 수 있고, 이후에는 원하는 Key를 기준으로 빠르게 값을 조회할 수 있으며 코딩 테스트에서 HashMap은 단독으로만 쓰이기보다 정렬, 문자열 처리, 완전 탐색, 투 포인터, 집합 Set
개념과 함께 자주 등장하기 때문에 단순히 문법만 익히기보다는 이 문제는 탐색보다 저장과 조회가 중요하다라고
판단하는 감각을 함께 익히는 것이 중요합니다.
마무리
HashMap을 정리하면서 느낀 핵심을 다시 정리해보면 다음과 같습니다.
HashMap은Key-Value구조를 기반으로 데이터를 빠르게 저장하고 조회할 수 있도록 해주는 자료구조입니다.- 해시 함수를 통해 데이터의 위치를 계산함으로써 평균적으로
O(1)의 성능을 가지며, 이는 탐색 시간을 크게
줄여줍니다. - 해시 충돌은 피할 수 없지만, 체이닝과 개방 주소법을 통해 이를 효율적으로 해결할 수 있으며, 구조에 따라 성능
특성이 달라집니다. HashMap은 단순한 컬렉션이 아니라, 문제 해결 과정에서 탐색을 최적화하기 위한 핵심 도구로 활용되는
자료구조입니다.